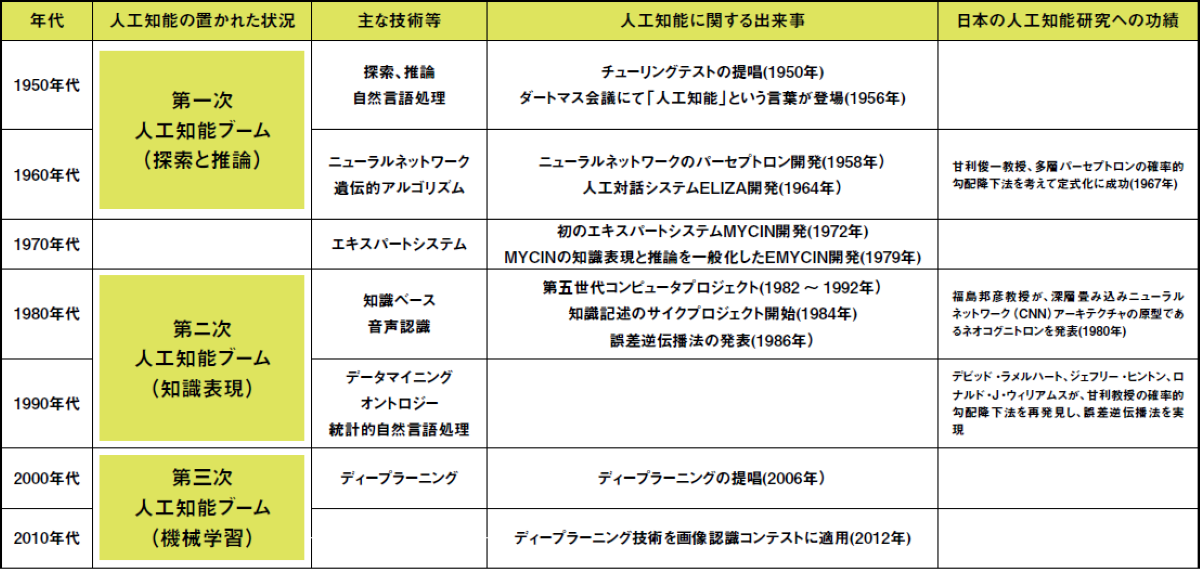
2024年のノーベル物理学賞を、ジェフリー・ヒントン氏とジョン・ホップフィールド氏が受賞した際に、いくつかのメディアが「なぜアマリではないのだ」と騒いでいたことを知っていただろうか。ここでいう「アマリ」とは、東京大学名誉教授の甘利俊一氏のことである。
甘利氏は、ヒントン氏とホップフィールド氏が研究を始めた1982年代に先駆けること10年前の1972年に、彼らが発見したニューラルネットワークの仕組みとほぼ同内容の論文を発表していた。実際にヒントン氏は、「自分の研究内容を最初に発見したのはアマリだ」とさまざまな場で発言している。
1970年代にニューラルネットワークと深層学習を研究していた日本人には、もう1人。福島邦彦氏もいる。福島氏は、AIの深層学習という概念を発想し、その実現のための理論を1978年には考案・確立した。
日本は、AIという概念の基礎となるニューラルネットワーク研究において、間違いなく世界に先駆けた地域だった。それが、どうして現在AIの後進国とみられるようになってしまったのだろうか。
最初に、AIが学習するとはどういうことなのか簡単に知っておく必要がある。生物の神経系には、ニューロンという細胞がある。このニューロン同士は、軸索と呼ばれる器官と樹状突起と呼ばれる器官で互いにつながっており、神経細胞が受けた情報を伝達しあっている。軸索と樹状突起が結合している部分をシナプスと呼ぶ。
このニューロン同士で情報を伝達するためのシナプスの結合強度は、外からの刺激で定期的に変化をする。たとえば、熱いものを触ってしまったという刺激を神経細胞が初めて感じた時、その刺激をほかのニューロンに伝えるためのシナプスが形成される。
初回は、細いシナプスでしかないが、2回目、3回目と熱いものに触れれば、そのシナプスはどんどんと太くなっていき、やがて熱いものに触れては痛い、怖いという反応につながる。これが、生物の学習だ。
シナプスへの刺激にあたる部分を電気信号のon/offで行い、繰り返される刺激による学習をコンピュータのon/offの回数などの重さを関数の値として置き換えれば、人間の学習のようなことが機械で再現できるのではないか。
この理論は、第二次世界大戦中から提唱されていたが、机上の空論としてさして注目されなかった。ところが、1967年、小脳の神経回路網の構造が判明し、空論だと思われていたモデルが、それほど現実と差異がないことが判明した。にわかに機械学習に対する研究熱が世界的に高まった。
こうして世界的にブームとなったAI研究であったが、その後、当時の推論では計算上学習に限界があることが証明されてしまい、1970年代に入る頃には、機械学習の研究ブームは落ち着いてしまった。ところが、日本だけは違った。
世界が機械学習をあきらめていくなか、甘利氏や福島氏のような日本人の研究者は、計算上限界だと思われていた壁を乗り越えようと必死に研究をしていたのだ。この時に発見された「確率的勾配降下法」や「ネオコグニトロン」といった成果が、現在のAI誕生の基礎技術となっていくとは研究をしていた当人たちも思っていなかったのかもしれない。





